|





|
| |
First Normal Form |
| |
Aim:
remove repeating groups. |
| |
|
| |
1NF
Rule 1: Take a copy of the original table Primary Key into the
new table entity as part any new (compound) key. |
| |
To make a link back to the originating table, a key is required
to make the inter-table relationship 'connection'.
|
| |
1NF
Rule 2: If there are repeating groups within repeating groups;
take the first repeating group out from the original group, then take
out the second group from the first, taking a copy of the original
key into a new table each time. |
| |
If groups of data repeat, as below, then you should
start by removing RENTALS from CAR, then work down removing
SERVICES & REPAIRS from RENTALS and then PARTS from SERVICES
& REPAIRS.
|
| |
|
| |
Below
is a list of data items from the MAINTENANCE DEPARTMENT data analysis.
|
| |
|
MAINTENANCE DEPARTMENT DATA |
|
CAR( |
| |
REGNO*
|
|
| |
MAKE
|
|
| |
MODEL
|
|
| |
UNIT
PRICE PER DAY
|
|
| |
CURRENT
MILEAGE
|
|
| |
NEXT
SERVICE MILEAGE)
|
| |
RENTALS(
|
|
| |
|
RENTALNO |
| |
|
DATE
OUT |
| |
|
DATE
IN |
| |
|
MILEAGE
OUT |
| |
|
MILEAGE
IN |
| |
|
MILEAGE
ALLOWANCE |
| |
|
EXCESS
MILEAGE) |
| |
|
SERVICES
& REPAIRS(
|
| |
|
|
GARAGE
NAME |
| |
|
|
GARAGE
ADDRESS |
| |
|
|
SERVICE
DATE |
| |
|
|
SERVICE
MILEAGE |
| |
|
|
SERVICE
COST) |
| |
|
|
PARTS(
|
|
| |
|
|
|
PART
CODE |
| |
|
|
|
PART
DESCRIPTION) |
Note:
‘repeating groups’ are signified by the underline, the RENTALS
data set is the same as the one Normalised
on the previous page. |
| The
above data items can be sorted into 4 related groups: Car, Rentals,
Servicing & Parts
An obvious point to start; is by creating a table
from the data, that contains NO repeating groups - the CAR data.
Each individual car, will have many occurrences of the other repeating
groups; a hire car will be serviced, rented
and have parts fitted, many times during it's working lifetime.
When creating this new table; as in the RENTALS
DEPARTMENT example; a unique record identifier needs to be chosen.
The registration number of every car is unique, short - only needing
a field length of 8 characters - and easy to memorise.
Therefore, REGNO will be the Primary Key for this
new table: It must also be added to each new Detail table created,
in order to act as a link to the Master table (CAR) and comply with
1NF rule 1.
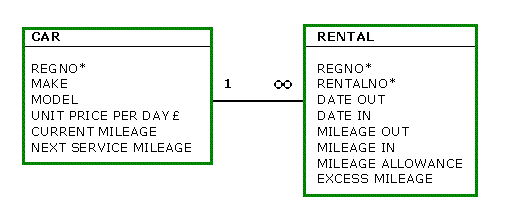
As the RENTALS data has already been Normalised,
then it can easily be added to the Master Car table as a Detail
table.
Using the existing key REGNO to act as a table join. A Car (just
like a Customer, in the previous example) can have many
Rentals, but a Rental can only be for one Car. Therefore this 1:M
relationship would be easily implementable.
|
|
|
So
what about the two remaining sets of data?
How can SERVICING & PARTS be joined to CAR? As stated previously
the Primary key from the Master table must be
transferred into every new table. So REGNO will become a key within
the SERVICING table.
The SERVICING data contains within
it, repeating groups of PARTS; as more than one part may be replaced
during servicing.
This should suggest to you that PARTS is the Many part of the SERVICING
& PARTS 1:M relationship. Additionally cars need
servicing many times: this means that SERVICING is the Many part
of a 1:M relationship with CAR.
So now we should set up two additional
tables SERVICING & PARTS - adding REGNO as a key to each.
The partial model for this data is
now taking shape:
|
|

|
The
next move is to add the SERVICING & PARTS data items:
Before, adding the remaining data items a few, common sense business
questions need to be considered;
What if Norm wanted to know which cars were the most expensive to
run or which car needed the most parts replacing;
You would expect reliability and running costs to be a primary consideration
for Norm when deciding on which model or
make of car to choose when replacing his hire car fleet.
As part of the database specification:
Using a simple query, Norm wants to be able to retrieve a current
repair cost
total for each of his hire cars; and compare the amounts charged
for parts by each garage.
If a database cannot perform simple business information summaries,
like running costs; then it does not meet the users
needs and is worthless - would you use a database system that did
not provide any additional or useful information?
No, you would buy one from a wide selection available that do!
Remember; that the Normalisation process is not only concerned with
efficiency and eliminating redundant & duplicate data.
While you are busy designing efficient database table joins using
Normalisation, you must also consider at design time
what the user wants & needs and how to deliver real, usable
relational database systems.
If you develop an UN-USABLE database, which does not satisfy the
customer's needs; the result is a project FAILURE.
Consider this: - If a car has had
many parts replaced during multiple services:
- during which service was a particular part replaced? Has the same
part been replaced more than once?
- which garage carried out the part replacement work? Does Norm
use more than one garage?
- can one garage fit all parts to any car? Or do garages specialise
(Kwikfit do not fit windscreens) in certain types of work?
|
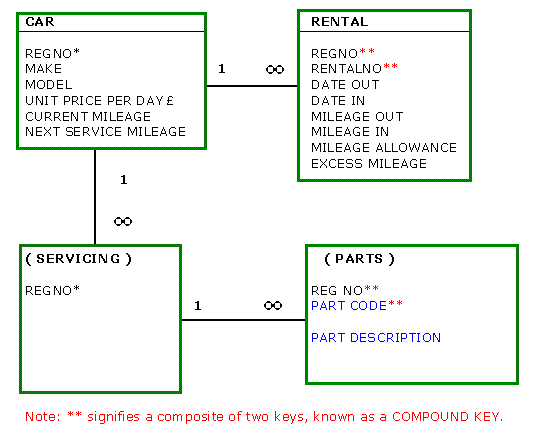
So how do these considerations affect Normalisation decisions? It
is now a case of working 'backwards' from PARTS to
SERVICING to CAR. What data must we know, to uniquely identify a particular
chosen part?
If we know the PART CODE, then we know the PART DESCRIPTION. So if
PART CODE is added to the existing REGNO key to
form a new (compound) key, here is a solution to the uniqueness problem
and a significant reduction in data duplication.
A data entry operator need now only type in say a 2 letter code (SM)
instead of a full textual description (Starter Motor).
Long textual descriptions like addresses should only be stored in
a database once; how often do give your post code to a
telephonist and they use the post code as a key to access your full
postal address. This is true database efficiency.
So our model now looks like this:
|
|
|
In
order to uniquely identify which part was fitted during which service
then other keys need to be created and added to
the existing REGNO + PART CODE Compound key. This part of the key
will create the required link to the SERVICING table.
Which items of SERVICE data could be used? How about the SERVICE DATE
& GARAGE NAME; these items will enable us to
know which garage replaced the part and when. And uniquely identify
the individual service any car had.
The combination REGNO, PART CODE, GARAGE NAME and SERVICE DATE key
may seem complicated.
However, try and think of another way to uniquely identify - 1) the
car that was serviced 2) the service date
3) which garage fitted the parts, and 4) which parts were fitted -
and hence satisfy Norm's query requirements.
Because, we need all four pieces of information, it follows that the
key will have four elements; each element uniquely
identifies only a quarter of the required data. But, putting the 4
parts together satisfies Norm's information requirements.
So the final, First Normal Form data
model looks like this:
|
|
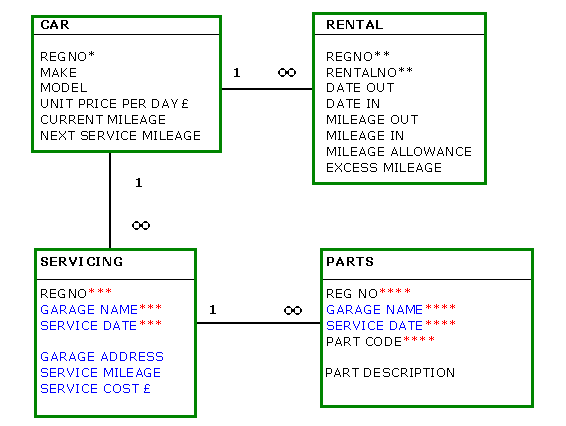
|
So
now that there are no repeating groups in the above data model; it
is time to check it with the 'rules of thumb' of 1NF.
- Is a copy of the Master table Primary key present in every Detail
table? - Yes, REGNO present in all tables.
- Do all linked tables have at least one attribute in common? - Yes,
REGNO present in all tables.
- Do all 'long' attributes occur only once in the 'one' part
of a 1:M relationship? - Yes, GARAGE ADDRESS occurs only once.
- Is the entity with the most keys the many part of a 1:M relationship?
- Yes, PARTS has 4 keys to SERVICING'S 3.
- Are all relationships 1:M? - Yes.
Thankfully, this was the most difficult
part of Normalising this particular data set - mainly due to Norm's
query requirements.
Click NEXT to continue with the Normalisation procedure - Yes, there
is more!
|
| <<<Back
to Normalisation Concepts |
Next
to Second Normal Form >>>
|
|
