N O R M A L I S A T I O N C O N C E P T S
| |
|
|
N O R M A L I S A T I O N C O N C E P T S |
| Home > Theory > Database Concepts > Database Types > |
|
|
| Home | Database Concepts | Database Types | 1 NF | 2 NF | 3 NF| 4-7 NF | |
|
|
Now we move on to the main purpose of this web site: the Normalisation Process Allow Norm to guide you through a case
study of a typical care hire business, following the methods and
rules of Normalisation, to transform a 'flat file' into a linked
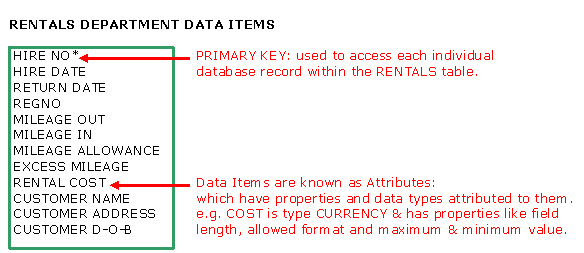
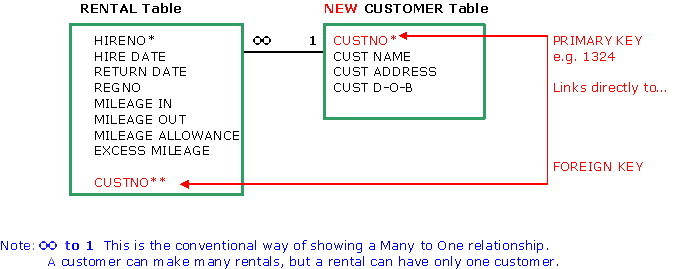
data structure that can be implemented in a relational database. Scenario: Norm's Car Rental Co. Norm's car hire company has two main departments - one dealing with car maintenance and the other dealing with the actual car rentals. Initially we are going to focus on the relatively simple rental department. (See 1NF page for the complete Normalisation of the much more complex Maintenance dept.) From data analysis, the following list of RENTAL data has been generated:
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||